
Akifumi Wachi
I am a Senior Chief Research Scientist at LY Corporation. My research interests lie primarily in reinforcement learning (RL), and span the entire theory-to-application spectrum from fundamental advances to deployment in real-world systems. Especially, I am interested in how a policy should and can be trained and deployed in safety-critical problems.
I am from Japan. My Japanese name is 和地 瞭良. 日本語ページは こちら
Research Interests
My core research interest is in reinforcement learning (RL) for reliable sequential decision making and AI Safety. My current research interests can be broadly organized into three overlapping groups:
- Safe RL: study how to develop RL approaches with certifiable safety guarantees.
- RL for Foundation Models: study how to apply RL for foundation models (e.g., safety alignment of language models).
- Adversarial Testing via RL: study how to utlize RL approaches for testing AI safety and finding failure cases.
Experiences
- 2025 May - present: Senior Chief Research Scientist, LY Corporation
- 2023 Oct - 2025 Apr: Chief Research Scientist, LY Corporation
- 2022 Sep - 202 Sep: Senior Research Scientist, LINE Corporation
- 2018 Apr - 2022 Aug: Research Scientist, IBM Research AI
- 2021: Ph.D. in Computer Science, University of Tsukuba
- 2018: M.S. in Aeronautics and Astronautics, University of Tokyo
- 2016: B.S. in Aeronautics and Astronautics, University of Tokyo
Selected Publications

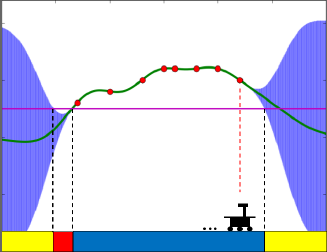
Failure-Scenario Maker for Rule-Based Agent using Multi-agent Adversarial Reinforcement Learning and its Application to Autonomous Driving
IJCAI, 2019
Publications
- Inference-Aware Meta-Alignment of LLMs via Non-Linear GRPO International Conference on Machine Learning (ICML), 2026. [PDF forthcoming]
- Sample-Efficient Hypergradient Estimation for Decentralized Bi-Level Reinforcement Learning International Conference on Automated Planning and Scheduling (ICAPS), 2026. [PDF forthcoming]
- Cost-Minimized Label-Flipping Poisoning Attack to LLM Alignment AAAI Conference on Artificial Intelligence (AAAI), 2026. [arXiv]
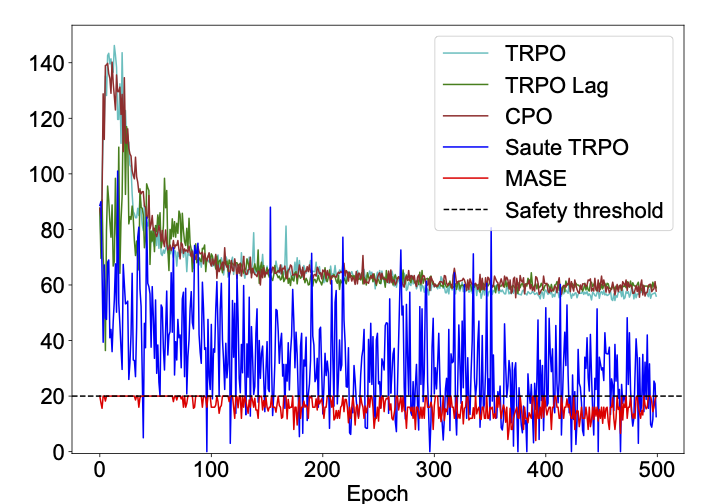
- A Provable Approach for End-to-End Safe Reinforcement Learning Neural Information Processing Systems (NeurIPS), 2025. [arXiv]
- Offline Guarded Safe Reinforcement Learning for Medical Treatment Optimization Strategies Neural Information Processing Systems (NeurIPS), 2025. (Spotlight) [arXiv]
- Target Return Optimizer for Multi-Game Decision Transformer Asian Conference on Machine Learning (ACML), 2025. [arXiv]
- Learning-Based Event-Triggered MPC With Gaussian Processes Under Terminal Constraints IEEE Transactions on Cybernetics, 2025. [IEEE]
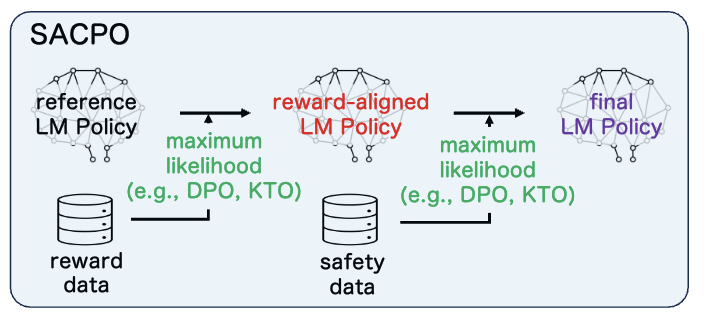
- Stepwise Alignment for Constrained Language Model Policy Optimizations Neural Information Processing Systems (NeurIPS), 2024. [arXiv] [Poster] [GitHub] [Hugging Face (SACPO)] [Hugging Face (P-SACPO)]
- Flipping-based Policy for Chance-Constrained Markov Decision Processes Neural Information Processing Systems (NeurIPS), 2024. [arXiv]
- A Survey of Constraint Formulations in Safe Reinforcement Learning International Joint Conference on Artificial Intelligence (IJCAI), 2024. [arXiv] [Poster] [Slide]
- Safe Reinforcement Learning Using Model Predictive Control with Probabilistic Control Barrier Function American Control Conference (ACC), 2024. [IEEE]
- Long-term Safe Reinforcement Learning with Binary Feedback AAAI Conference on Artificial Intelligence (AAAI), 2024. [PDF] [Poster] [Slide]
- Safe Exploration in Reinforcement Learning: A Generalized Formulation and Algorithms Neural Information Processing Systems (NeurIPS), 2023. [PDF] [arXiv] [Poster] [Video]
- Safe Policy Optimization with Local Generalized Linear Function Approximations Neural Information Processing Systems (NeurIPS), 2021. [PDF] [OpenReview] [arXiv] [Poster]
- Polar Embedding The SIGNLL Conference on Computational Natural Language Learning (CoNLL), 2021. [PDF]
- Neuro-Symbolic Reinforcement Learning with First-Order Logic Empirical Methods in Natural Language Processing (EMNLP), Short paper, 2021. [PDF]
- Language-based General Action Template for Reinforcement Learning Agents Association for Computational Linguistics (ACL), Findings, 2021. [PDF]
- Q-learning with Language Model for Edit-based Unsupervised Summarization Empirical Methods in Natural Language Processing (EMNLP), 2020. [PDF] [arXiv]
- Safe Reinforcement Learning in Constrained Markov Decision Processes International Conference on Machine Learning (ICML), 2020. [PDF] [arXiv] [Slide] [Video]
- Failure-Scenario Maker for Rule-Based Agent using Multi-agent Adversarial Reinforcement Learning and its Application to Autonomous Driving International Joint Conference on Artificial Intelligence (IJCAI), 2019. [PDF] [arXiv] [Slide] [Poster] [Simulation]
- Safe Exploration and Optimization of Constrained MDPs using Gaussian Processes AAAI Conference on Artificial Intelligence (AAAI), 2018. [PDF] [Slide]
- Integral Design Method for Simple and Small Mars Lander System Using Membrane Aeroshell Acta Astronautica, 2018. [PDF]
- The Conceptual Design of a Novel Simple and Small-sized Mars lander IEEE Aerospace Conference, 2018. [PDF]
- Mars Entry, Descent, and Landing by Small THz Spacecraft via Membrane Aeroshell AIAA SPACE and Astronautics Forum and Exposition (AIAA SPACE), 2017. [PDF] [Slide]
- Hazard Avoidance Control Using Stochastic Optimization for Mars Safe Landing International Symposium on Space Technology and Sciences (ISTS), 2017.
- Low-Thrust Trajectory Design to Improve Overall Mission Success Probability Incorporating Target Changes in Case of Engine Failures International Symposium on Space Technology and Science (ISTS), 2017. Best Student Paper Award (First Prize) [PDF]
- Fault-Tolerant Low-Thrust Trajectory Design with Backups for Multiple Targets IFAC Symposium on Automatic Control in Aerospace (ACA), 2016. Best Student Paper Award (First Prize) [PDF]
Demo
- LOA: Logical Optimal Actions for Text-based Interaction Games Association for Computational Linguistics (ACL), Demo Paper, 2021. [PDF]
Patents
- I have over 10 filed patents. See Google Patents
Professional Activities
Conference Program Committee Member
- ICML, NeurIPS, ICLR, AISTATS, AAAI, IJCAI, COLM, ACL, EMNLP, CoRL
Journal Reviewer
- ACM Transactions on Evolutionary Learning and Optimization (Associate Editor)
- IEEE Transactions on Pattern Analysis and Machine Intelligence
- Transactions on Machine Learning Research (TMLR)
Others
Awards
- Silver Reviewer (Top 50%) of ICML 2026
- Top Reviewer of NeurIPS 2024 [link]
- Dean’s Award (Second Prize), from Faculty of Engineering, The University of Tokyo, 2018
- Best Student Paper Award (First Prize), Joint Conference: 31st ISTS, 26th ISSFD, and 8th NSAT, 2017
- Best Student Paper Award (First Prize), IFAC Symposium on Automatic Control in Aerospace (ACA), 2016, [link]
Fellowships
- Financial support to participate in Thirty-second AAAI conference on Artificial Intelligence by Society for Promotion of Space Science (SPSS), February, 2018
- Financial support to participate in International Astronautical Congress (IAC) by the Japan Society for Aeronautical and Space Sciences (JSASS), September, 2017
- Go Global Scholarships 2016 Short Study Abroad Scholarships: the University of Tokyo, 2016
- Fellowship of the Leading Graduates Schools Program: Global Leader Program for Social Design and Management by the Ministry of Education, Culture, Sports, Science and Technology in Japan, 2016
Invited Talk
- Safe Reinforcement Learning,
Guest Speaker Session at Cohere for AI,
Online, February, 2024
[Cohere Website] [Presentation Slide]